
Аутоматизовање уноса Википодатака и интегрисање са другим веб ресурсима
Википодаци (енгл. Wikidata) су база знања Задужбине Викимедија која представља заједнички извор различитих врста података, како конкретних тако и апстрактних. Похрањене податке могу да користе и други Викимедијини пројекти, као што је Википедија, али и шира заједница за различите намене.
У циљу популаризовања Википoдатака, Викимедија Србије и Рударско-геолошки факултет су заједно покренули пројекат Коришћење википодатака за проналажење информација, обележавање ентитета и унапређење садржаја на вебу. Иницијално је пројекат био замишљен нешто другачије, али је прилагођен актуелној ситуацији изазваној пандемијом новог корона вируса (covid-19), након чега је примењен модификован приступ, који је можда по значају и резултатима превазишао планирано.
У овом посту ћемо се осврнути управо на примере интеграције Википодатака са екстерним системима и могућностима убрзања изградње овог драгоценог складишта података. Подухват је био инспирисан пројектом Scholia (Q45340488), који за представљање библиографских информација, научних профила аутора и институција користи Википодатке. Видевши конкретно scholiaEvent и scholiaTopic, покренута је слична акција, да се на основу постојећих података креирају повезани (RDF) подаци о ауторима и радовима за часопис Инфотека и на званичном сајту часописа прикаже граф коауторства као интерактивну страницу. Имплементација представља студију случаја која се може даље проширити на друге часописе, као и на друге случајеве употребе. Scholia се развија у оквиру веће иницијативе WikiCite, која настоји да индексира библиографске метаподатке у Википодацима о ресурсима који се могу користити за поткрепљивање тврдњи изнетих на Википодацима, Википедији или негде другде. У времену када смо преплављени нетачним информацијама на вебу, одговарајуће поткрепљивање информација релевантним изворима сигурно игра важну улогу. Како смо желели да аутоматизујемо колико год је могуће процес припреме и уноса података, истражили смо различита решења од којих смо користили два: OpenRefine и QuickStatements, о чему ће више речи бити у наредним одељцима.
Шта су то заправо Википодаци и чему служе?
Шта Википедија каже? Википодаци (енгл. Wikidata) су база знања чија је сврха да буде заједнички извор одређених врста података (нпр. датуми рођења), које користе други Викимедијини пројекти као што је Википедија. У том смислу је слична Викимедијиној остави где се складиште медијске датотеке којима се приступа са других Викимедијиних пројекта.
Википодаци су оријентисани на документе, усредсређени на ставке, које представљају теме, концепте или објекте. Свакој ставци додељен је јединствени, трајни идентификатор, позитиван цео број са префиксом великог слова Q, познатог као „QID“. Ово омогућава превођење основних информација потребних за препознавање теме коју ставка покрива, а да се не фаворизује било који језик, а да се обезбеди јединственост значења конкретног појма.
ВИКИПОДАЦИ СЕ УПРАВО УКЛАПАЈУ У ТРЕНДОВЕ РАЗВОЈА ИНФОРМАЦИОНИХ ТЕХНОЛОГИЈА, КОЈЕ ПОМЕРАЈУ ГРАНИЦЕ ОД МАШИНСКЕ ЧИТЉИВОСТИ КА МАШИНСКОЈ РАЗУМЉИВОСТИ ПОДАТАКА НА ВЕБУ.
Наведимо неке примере ставки: места (Београд, Q3711), особе (Душко Радовић, Q1268210), догађаје (Бој на Косову, Q3495274), предмете (лопта, Q18545), појмове (љубав, Q316), романи (На Дрини ћуприја, Q1247865),… Концепти који стоје иза ставки треба да буду јединствени, али се дешава да постоје две ставке под истим називом, Елвис Присли“: Елвис Присли (Q303) представља америчког певача и глумца, а Елвис Присли (Q610926) представља његов истоимени албум. Дакле, ставка је повезана са јединственим идентификатором (QID), идентификатор је повезан са паром: насловом и описом, како би се уклонила било каква двосмисленост. Можемо имати опште ставке, али такође и лексеме везане за апстрактне појмове.
Идентификатор ставке (QID), осим што је повезан са насловом и описом, може имати више псеудонима и одређени број изјава (тврђања, израза) којима се представљају њена својства и вредности. Изјава је уређена тројка: (ставка, својство, вредност), где је ставка (Q) – било која тема (особа, предмет, место, концепт), својство (P) – релација или карактеристика релевантна за ставку (нпр. пол за људе (P21), главни град за државе (P1376), дужина (P2043) за реке и вредност – или сам “литерал” (нпр. дужина Дунава је 2860 км) или референца на неку другу ставку (нпр. главни град Србије је Београд). Ставка може бити описана низом изјава од којих свака даје једну чињеницу или податак о ставки.
Како би се у Википодацима записали следеће информације?
Сава је река која се улива у Дунав. Сава извире у Словенији. Њена притока је Дрина.
Па у бази Википодаци би се то записало овако:
Q14383 P31 Q4022. Q14383 P403 Q1653. Q14383 P205 Q215. Q14383 P974 Q186901.
У претходном примеру имамо четири тројке, односно четири реченице облика субјекат-предикат-објекат. Ако желимо да прецизније се изразимо, рећи ћемо да су то RDF тројке, где је RDF скраћеница од Resource Description Framework (Q54872), односно оквир за описивање ресурса на вебу.
Важна карактеристика Википодатака је да имају два лица: једно намењено људима и друго: намењено машинама, што омогућава бројне примене у обради природних језика, поменимо неке: класификација текста, индексирање, анализа текста, генерисање текста, сумаризација, нормализација, повезивање и сл.
Друга важна карактеристика је вишејезичност, свака ставка се може повезати са лабелом на било ком језику који је регистрован на Викимедијиним ресурсима, што отвара пут бројним применама од аутоматског превођења, класификације вишејезичних докумената до анализе садржаја на вебу и друштвеним мрежама.
Шта се желело постићи пројектом?
Отвореност Википодатака за континуално проширење и допуна ресурса, односно могућност да заједница континуално унапређује Википодатке је мотивисала тим окупљен око овог пројекта. На Рударско-геолошком факултету Универзитета у Београду (Q12758413), већ две године студенти уносе википодатке о рудницима у Србији, налазиштима руда, рударским машинама и сл., али се показало да то може брже и боље. Наиме, како је појединачан унос података често временски зависан посао, јавила се идеја да се искористе неки постојећи подаци, похрањени у различитим дигиталним форматима и полуаутоматски увезу у Википодатке. Дакле, основна идеја је да се убрза унос података, првенствено на српском, података о резултатима истраживања у области дигиталне хуманистике у Србији и старих српских романа. Тиме би се подигла видљивост уједно и српског језика, нашег културног наслеђа и резултата истраживања у Србији, а свакако отворио пут и за многе друге скупове података.
ОСНОВНА ИДЕЈА ПРОЈЕКТА ЈЕ ДА СЕ УБРЗА УНОС ПОДАТАКА О РЕЗУЛТАТИМА ИСТРАЖИВАЊА У ОБЛАСТИ ДИГИТАЛНЕ ХУМАНИСТИКЕ У СРБИЈИ И СТАРИХ СРПСКИХ РОМАНА, ЧИМЕ БИ СЕ ПОДИГЛА ВИДЉИВОСТ УЈЕДНО И СРПСКОГ ЈЕЗИКА И КУЛТУРНОГ НАСЛЕЂА.
Концепт семантичког веба и технологије отворених повезаних података, проширују традиционални веб употребом стандарда, језика за означавање и сродних алата за обраду, где управо RDF има велику улогу и омогућава ефикаснија решења за проналажење информација. Да би семантички веб функционисао рачунари треба да имају приступ структурисаним колекцијама информација и да утврде дефинисана правила аутоматизованог управљања. Википодаци се управо уклапају у те трендове развоја информационих технологија, које померају границе од машинске читљивости ка машинској разумљивости података на вебу.
Када се кренуло у првобитну идеју да се уради повезивање именованих ентитета показало се да недостаје велика количина података у Википодацима, а да ти подаци постоје у неким другим јавним или доступним базама, те су активности усмерене прво на аутоматизацију попуњавања Википодатака, како би касније повезивање било ефикасније и потпуније
Постигнути резултати
Прве активности су везане за упознавање студената са актуелним садржајима везаним за рударство и минералне ресурсе у Википодацима, приказивање података на различите начине: табеларно, графички, на карти и слично, након чега су поредили садржаје база података, табела и онлајн података са садржајем у бази и допуњавали новим изјавама постојеће ставке и додавали нове ставке где је било потребно. Тиме је креиран прилично ажуран преглед рудника у Србији, али и у региону, јер су студенти из Босне и Херцеговине и из Црне Горе уносили податке из њихових земаља. За ставке рудника и лежишта минералних сировина су наведене минералне сировине које производи (P1056), годишња производња, управно-територијална јединица тј. округ (P131), фирма која обавља експлоатацију или истраживање, када је основан (P571), историјски период (P2348), геолокација (P625), површина (P2046), понегде слика (P18), сајт (P856), веза ка страни на Википедији уколико постоји и идентификатор ка географској вишејезичној бази Геонејмс (P1566). Наведимо пример рудника „Соко” (Q62565070). За рударске компаније су унети основни јавно доступни подаци. Што се тиче рударске механизације задржали смо се на основној рударској механизацији, на пример роторни багер. Осим креирање и претраживања Википодатака, пажња је посвећена и вишејезичности, где су општи концепти превођени на српски уколико превод није постојао, што је нарочито важно за успостављање стандардизоване терминологије у областима које се брже развијају него што терминологија успева да се стандардизује. Како би схватили неке од могућности Википодатака, показани су SPARQL упити и неколико типичних образаца им је дато као основа за даља истраживања ресурса.
Осим студената РГФ-а, са концептима ове области су упознати и студенти на докторским студијама Интелигентни системи при Универзитету у Београду, где им је представљен концепт семантичког веба и технологије отворених повезаних података, са акцентом на Википодатке, њихово претраживање комплексним упитима, различитим визуелних репрезентацијама али и могућностима масовног ажурирања.
У сарадњи са Друштвом за језичке ресурсе и технологије ЈеРТех које се бави промоцијом, популаризацијом и унапређивањем свих грана језичких технологија на научном, стручном и практичном нивоу се кренуло у анализу потребних алата и припрему података. Часопис Инфотека који се публикује у отвореном приступу, а који уз то излази двојезично
Да би аутоматизација уноса била могућа, први корак који је требало урадити јесте прикупљање и припрема података. Други корак се односи на избор лабела у подацима које ће се користити за идентификацију предиката и креирање шеме. Шемом дефинишемо повезивање вредности са ставком, односно субјектом помоћу предиката као посредника.
Иако је крајњи циљ унос података о радовима, унос њихових аутора је био неизоставан корак и предуслов даљем раду. По завршеном уносу креирани су SPARQL упити за различите приказе, користећи и интегрисане технологије у Википодацима за визуализацију резултата
Сваки рад из двојезичне дигиталне библиотеке Библиша је повезан са припадајућим википодацима, тако да може директно да се дође до конкретног, појединачног приказа у википодацима, али и да се интегришу неки од корисних визуалних приказа у оквиру саме апликације. Пример једног рада:

на језик Википодатака би се преводио на следећи начин:
“Вики технологија – настанак, развој и значај” (Q99231414)
instance of (P21) academic journal article (Q18918145)
author P(50) Ђорђе Стакић (Q99281526)
Може се видети да је рад представљен идентификатором Q99231414, да је примерак (P21) класе академских чланака(Q18918145) и да има аутора Q99281526.
Алат OpenRefine, који је иницијално развио Google, и QuickStatements који је развио члан тима Википодатака Magnus Manske се често користе заједно, може се рећи да се допуњују. QuickStatements користи текстуални TSV или CSV формат који се ефикасно генерише алатом OpenRefine. Зашто су потребна оба алата? OpenRefine уноси измене у једном кораку, па разрешавање грешака може довести до дуплицирања података, док QuickStatements појединачно уноси сваку ставку и омогућава боље праћење процеса импорта. Препорука је да се OpenRefine користи за припрему за унос у базу Википодатака, а физички унос RDF тројки урадити коришћењем alata QuickStatements.
Дакле шта би били кораци? Прво се припреме подаци као CSV датотека, креира се OpenRefine пројекат и подаци учитају. Даље следи препознавање постојећих ставки у Википодацима – неопходан корак који треба да омогући повезивање садржаја датотеке са QID постојећих ставки и унос нових уколико оне не постоје. У овој фази је ручна провера и евентуална промена неоходна. Креирање схеме скупа за унос дефинише предикате који ће повезивати субјекте и објекте у RDF тројкама и врло је важан корак. Након уноса података за 120 радова креиран је HTML који интегрише сервис за постављање упита Wikidata Query Service са Библишом. Написани су упити који добављају табеле: последњих објављених радова, заступљености кључних речи у радовима, слике аутора, табелу профила аутора, граф коауторства, дистрибуције аутора по полу, и сл. Подаци о ауторима обухватају елементарне податке које свакако у наредном периоду треба допунити новим садржајима: институција у којој раде, области истраживања, референце ка референтним истраживачким базама и сл.
На слици се може видети део графа коуторства који вуче википодатке путем Сервиса за претрагу Wikidata Query Service.

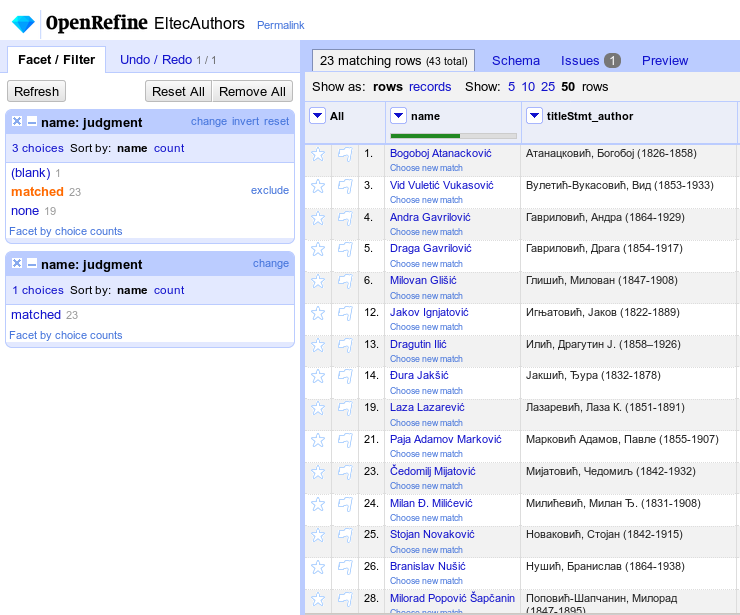
Тренутно је у току унос података о романима и ауторима романа у Википодатке из дигиталне библиотеке ELTEC (European Literary Text Collection) коју ће да чини 100 српских романа из периода 1840 — 1920. која се развија у оквиру Cost акције: CA16204 – Distant Reading for European Literary History којој се Друштво ЈеРТех активно укључило. Припремљен је скуп метаподатака за 79 романа који су до сада дигитализовани и припремљени према захтевима Акције. У питању су дела укупно 42 аутора, од тога 27 је већ у Википодацима. На слици можемо видети део припреме скупа аутора за унос у Википодатке.
Повезивање Википодатака са апликацијом Аурора је у току, што се може видети на следећој слици. По завршетку уноса ће се и овде наћи занимљиви графови.


„Рад на Википодацима видимо као континуалну активност, при чему ће се посебна пажња обратити на повезани отворене податке из области лингвистике (LLOD http://linguistic-lod.org/llodcloud) и њихове примене. Морамо бити свесни свакако проблема и ограничења Википодатака и других отворених повезаних података како би истражили могућности њиховог превазилажења или бар ублажавања.
Имајући у види да се својства ређе додају, треба увек добро истражити стране сличних својстава, пре него се одлучимо на њихово додавање. Пажњу посветити и ограничењима која постоје на својствима која се могу видети у сугестијама при уносу. Корисно, нарочито за оне који воле да се баве додатним алатима, је да погледају стране са алатима. Fusion команда може бити од користи за спајање грешком дуплираних података.
Повезивање ентитета коришћењем википодатака (named entity linking, NEL) је област која је овим пројектом само дотакнута, а представља врло актуелну тему, која доприноси машинском разумевању садржаја на вебу. Нека од светских искустава се могу применити, али специфичности српског језика ипак захтевају специфичне начине прилагођавања.
Коришћење википодатака за израду динамичких вики карата (mapframe) и повезивање википодатака са другим семантичким ресурсима на вебу ће се наставити у већем обиму.”, рекла је руководилац пројекта др Ранка Станковић, ванредни професор и шеф Катедре за примењену математику и информатику, уједно и шеф Рачунарског центра РО РГФ.
Будућност Википодатака
Википодаци су заиста огромна база знања, која је 1) доступна свима – за читање информација, постављање упита, уређивање и унапређивање; 2) отворена – вишеструка употреба обезбеђена бесплатним Creative Commons CC0 лиценцом, која даје пуну слободу за коришћење података; 3) вишејезична – ентитети се могу именовати и описивати на било ком природном језику. Ова три кључна својства су кључни покретачи за бројне апликације, што верујем да још више инспирисати вики заједницу да се овом ресурсу посвети. Такозвани мали језици, какав је српски, треба да користе све начине да се изборе за своје место у дигиталном простору, па активности на овом пројекту и сродним пројектима и иницијативама видимо као скроман допринос очувања српског језика у дигиталном добу.
Радна акција припреме романа за дигиталну библиотеку старих српских романа се наставља и позивамо све заинтересоване да се јаве за читање и кориговање, о чему се могу информисати овде. Рад на уносу нових скупова података се свакако наставља и позивамо све заинтересоване да се јаве путем корисничке стране Ranka Stanković — Wikidata.
Ауторка текста: др Ранка Станковић, руководилац пројекта, ванредни професор и шеф Катедре за примењену математику и информатику, уједно и шеф Рачунарског центра РО РГФ